Risk Tiering: How L0-L4 Classification Actually Works
Most AI code review tools use AI to judge risk. That is backwards. GuardSpine uses deterministic classification: metadata and content patterns, not model judgment.
Most “AI code review” tools use AI to judge risk. That is backwards. If AI is writing the code, AI should not also be the sole judge of whether it is safe. GuardSpine uses deterministic classification: metadata and content patterns, not model judgment.
This distinction matters more than it sounds like it should. Let me explain why.
The Problem with AI-Judged Risk
You have an AI assistant that just rewrote your authentication middleware. Now you feed that rewrite into another AI model and ask: “Is this risky?”
Think about what you are actually doing. You are asking a system that cannot reason about security consequences to evaluate the security consequences of code written by a system that cannot reason about security consequences. The second model does not know your threat model, your compliance requirements, your deployment topology, or what happened the last time someone changed this file. It knows token patterns.
Sometimes the AI gets the risk assessment right. Sometimes it does not. The problem is that you cannot tell which case you are in without already knowing the answer. That defeats the purpose of automated risk assessment.
Deterministic classification does not have this problem. It does not guess. It matches patterns. The patterns are defined by humans who understand the codebase, the compliance requirements, and the risk model. The classifier applies those patterns consistently, every time, without hallucinating context it does not have.
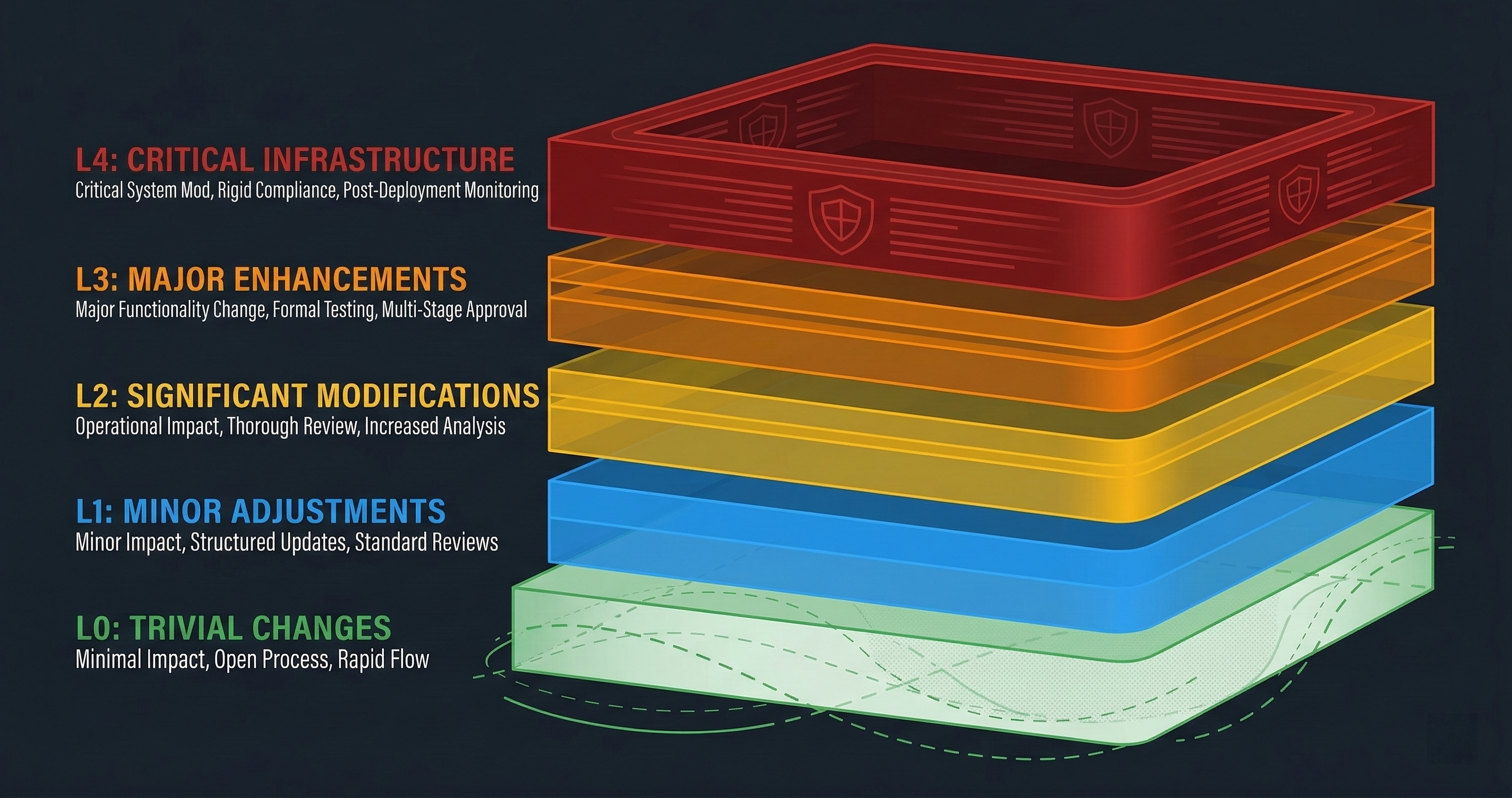
The Five-Tier Advanced Model
GuardSpine’s advanced risk tiering has five levels. Each maps to a specific class of change and a specific review requirement.
L0: Negligible
Changes that cannot meaningfully affect system behavior. Whitespace formatting. Comment updates. Documentation edits. CSS-only changes to non-functional elements. Test file modifications that do not touch production code.
Review requirement: auto-approve. No human or AI review needed. The evidence bundle still gets created — governance does not mean slowing everything down, it means having proof of what happened.
L1: Low
Changes with minimal blast radius. Renaming a local variable. Adding a log statement. Updating a string literal in a non-security context. Modifying test assertions.
Review requirement: auto-approve with recording. Same as L0 in practice, but the policy engine notes these changes in case a pattern emerges. Ten L1 changes in the same auth module over a week might warrant a look, even if each individual change is low risk.
L2: Moderate
Changes that affect behavior but are contained within well-understood boundaries. New feature code that does not touch auth, payments, or PII. Refactoring that changes function signatures. Dependency version bumps for non-security packages. Database schema changes for non-sensitive tables.
Review requirement: AI council review. Multiple models review the diff independently. If they agree the change is safe, it proceeds. If they disagree, it escalates.
L3: Elevated
Changes to sensitive subsystems. Authentication logic. Authorization rules. API key handling. Session management. Encryption configuration. PII processing pipelines. Anything that touches the security boundary.
Review requirement: AI council review with explicit approval tracking. The council reviews, but the approval is recorded with reviewer identities, rationales, and timestamps. A human can inspect the trail.
L4: Critical
Changes to the highest-risk components. Payment processing logic. Cryptographic implementations. Infrastructure-as-code for production environments. CI/CD pipeline modifications. Security middleware. Anything where a mistake has direct financial, legal, or safety consequences.
Review requirement: multi-model council review with human attention flag. The AI council reviews, the change gets flagged for human awareness, and the evidence bundle includes a prominent marker that this was a critical-tier change. Your compliance team can set up alerts on L4 bundles.
The Three-Tier Simple Model
Not every team needs five tiers. Some teams are just starting with governance and want something simpler. The three-tier model collapses the five tiers into three gates:
AUTO — Equivalent to L0 and L1. Changes are auto-approved. Evidence bundles are created but no review blocks the merge.
REVIEW — Equivalent to L2 and L3. Changes require review before proceeding. The review can be AI-only or AI-plus-human depending on your configuration.
BLOCK — Equivalent to L4. Changes cannot proceed without explicit approval. The merge is blocked until a designated approver signs off.
You pick which model to use in your configuration:
classification:
mode: simple # or "advanced"
blockTier: BLOCK # which tier blocks merges
gateType: review-required # or "auto", "block-all"
How Classification Actually Works
Here is the part most people want to know: how does a code change get assigned to a tier?
The classifier does not read the code and think about it. It matches the change against a set of patterns and rules. These patterns are deterministic — the same input always produces the same output.
File Path Patterns
The first and simplest classifier. If the file is in src/auth/, it is at least L3. If it is in src/payments/, it is L4. If it is in tests/, it is L0. If it is *.css, it is L0.
patterns:
- path: "src/auth/**"
min_tier: L3
- path: "src/payments/**"
min_tier: L4
- path: "**/*.test.*"
max_tier: L0
- path: "**/*.css"
max_tier: L0
- path: "infrastructure/**"
min_tier: L4
- path: ".github/workflows/**"
min_tier: L4
Notice min_tier vs max_tier. A file in src/auth/ is at least L3, but could be elevated to L4 by content patterns. A test file is at most L0, regardless of what the content patterns say.
Content Patterns (Sensitive Pattern Detection)
The classifier scans the diff content for patterns that indicate sensitivity:
Authentication patterns: password, credential, auth_token, session, jwt, oauth, saml, login, logout, mfa, 2fa, totp. Any diff that adds, modifies, or removes lines containing these patterns gets elevated.
Cryptographic patterns: encrypt, decrypt, hash, hmac, aes, rsa, private_key, public_key, certificate, tls, ssl, cipher. Cryptography changes are almost always L3 or L4.
PII patterns: ssn, social_security, date_of_birth, email_address, phone_number, address, passport, medical_record, health_data. Any PII handling change needs elevated review.
Financial patterns: payment, charge, refund, invoice, billing, price, amount, currency, transaction, ledger, account_balance. Financial logic is high stakes.
Infrastructure patterns: dockerfile, docker-compose, terraform, ansible, kubernetes, k8s, helm, env_var, secret, api_key, connection_string. Infrastructure changes affect the blast radius of everything else.
These patterns are not regular expressions that match blindly. The classifier checks the diff context — it distinguishes between adding // TODO: implement password reset (a comment, L1) and modifying const passwordHash = bcrypt.hash(password, rounds) (auth logic, L3).
Metadata Signals
Beyond file paths and content, the classifier considers:
- Number of files changed: A 50-file change gets elevated regardless of content. Large changes are harder to review correctly.
- Lines of code added/removed: Massive additions or deletions warrant attention.
- File types: Binary files, configuration files, and lock files have their own risk profiles.
- Change history: If this file has been changed frequently in recent PRs, it might be under active development (lower risk) or under repeated patching (higher risk, investigate).
The Classification Algorithm
The final tier is computed as:
- Start with the file path pattern match. If
min_tieris set, that is the floor. Ifmax_tieris set, that is the ceiling. - Scan diff content for sensitive patterns. Each match can elevate the tier (but never above a
max_tierceiling). - Apply metadata signals. Large changes or unusual patterns can add one tier.
- Take the maximum tier across all change units in the PR. A PR that touches one L4 file is an L4 PR.
Step 4 is important. Risk does not average. If you change a CSS file (L0) and a payment handler (L4) in the same PR, the PR is L4. The highest-risk change determines the review requirements for the entire batch.
Why Deterministic Beats Probabilistic
Three reasons.
Auditability. When an auditor asks “why was this change classified as L3?” you can point to the exact pattern that matched and the exact rule in the configuration. There is no “the model thought it looked risky.” There is “line 47 matched the auth_token pattern in content scanning, and the file is under src/auth/, which has a minimum tier of L3.”
Consistency. Run the same classifier on the same diff tomorrow, next week, next year. Same result. AI models drift. They get updated. They respond differently to the same prompt depending on context window contents, temperature, and version. Deterministic classification does not drift.
Composability. Because the rules are data (YAML configuration), you can version them, diff them, review them, and evolve them using the same governance process you use for code. Your risk classification policy is itself a governed artifact.
Configuring for Your Team
The default patterns cover the most common cases. But your codebase is not generic. You might have a src/financial-models/ directory that should be L4. You might have a scripts/ directory that is always L0 because it only contains developer tooling. You might have specific function names that should trigger elevation.
Add patterns to .guardspine/config.yml:
classification:
mode: advanced
blockTier: L4
gateType: review-required
custom_patterns:
- path: "src/financial-models/**"
min_tier: L4
reason: "Financial model changes require full review"
- path: "scripts/dev-tools/**"
max_tier: L0
reason: "Internal developer tooling"
- content: "HIPAA|PHI|protected_health"
min_tier: L4
reason: "Protected health information handling"
- content: "TODO|FIXME|HACK"
elevate: 1
reason: "Technical debt markers in production code"
The elevate option adds N tiers to whatever the base classification would be. A change that would normally be L1 becomes L2 if it contains TODO markers. This is useful for catching patterns that are not inherently risky but indicate incomplete work that should not ship without review.
The AI Council Comes After, Not Instead
Classification happens before the AI council reviews the code. This is the critical architectural decision.
The AI council does not decide the risk tier. The deterministic classifier decides the risk tier. The AI council then performs a review appropriate to that tier. An L2 change gets a standard review. An L4 change gets an intensive review with multiple models and explicit approval tracking.
This means the AI is constrained by the policy, not the other way around. If the classifier says L4, the AI cannot downgrade it to L1 because “it looks fine.” The tier is set by rules. The AI works within those rules.
Could we let the AI suggest tier adjustments? Yes, and some teams do configure that. But the suggestion goes into the evidence bundle as a guardspine/rationale item. It does not change the classification. A human can read the rationale and decide to adjust the rules. The adjustment happens in the configuration, not in the model’s head.
This separation — deterministic classification, then AI-assisted review within the classification’s constraints — is what makes the system auditable. The deterministic part is provably correct (it matches the rules). The AI part is recorded and reviewable (it is in the evidence bundle). Neither depends on the other’s correctness to be useful.
What Tier Should You Start With
If you are just getting started, use the three-tier simple model. Set blockTier: BLOCK and gateType: review-required. This means everything gets reviewed, and BLOCK-tier changes stop the merge until someone approves.
After a week, look at your evidence bundles. If most changes are AUTO and the reviews on REVIEW changes are mostly “looks fine,” your classification is working. If you are getting too many false positives (low-risk changes classified as REVIEW), add max_tier patterns for the directories that are triggering unnecessarily.
After a month, consider switching to the five-tier model if you want finer-grained control. By then you will have enough data in your evidence bundles to know where the real risk concentrations are in your codebase.
Book a call if you want help tuning your risk classification for your specific codebase. I have done this for teams ranging from 5 to 500 developers.