
PR Approval Is Not Evidence
GitHub shows that someone clicked approve. It doesn't show what they reviewed, what risks were present, or why approval was reasonable. That distinction just became expensive.
AI coding assistants doubled delivery speed.
They also broke a quiet assumption: that a PR approval proves meaningful review.
The Pattern I Keep Encountering
When I audit AI implementations at companies using Copilot or Cursor, I see the same failure mode:
- Team adopts AI coding tools
- PR throughput triples
- Review quality stays flat (or drops)
- Auditor asks “how did this payment logic change get approved?”
- Engineering points to a green checkmark
That checkmark proves exactly one thing: someone clicked a button.
It doesn’t prove what diff they actually saw. It doesn’t prove the review happened before someone force-pushed. And it definitely doesn’t prove the approver understood the security implications.
Why This Matters Now
I’ve sat in SOC 2 audits where the evidence package was essentially:
- Screenshot of GitHub approval
- “Trust us, they reviewed it”
That worked in 2022. Auditors accepted it because the assumption held: humans wrote most code, reviews were slow, diffs were small.
Now? AI assistants generate hundreds of lines in seconds. The assumption broke. Auditors are catching up.
The shift happened faster than most compliance teams expected. In 2023, auditors rarely asked about AI-generated code. By mid-2024, it was a standard line item. The firms I work with are now seeing explicit questions about AI tooling in their audit questionnaires.
The questions I’m hearing from compliance teams:
- “Can you prove the diff at approval time matches what was merged?”
- “What was the risk classification process?”
- “How do you know the reviewer saw the sensitive changes?”
Most teams answer honestly: “We can’t.”
What Happens Without This
The failure mode isn’t dramatic. It’s slow and expensive.
First, audit findings start accumulating. Each one requires remediation documentation. That’s engineering time diverted from shipping.
Then insurance renewals get complicated. Cyber liability underwriters are asking about code review processes. “We use GitHub approvals” is becoming an insufficient answer.
The real cost is invisible: the security incident that traces back to AI-generated code that nobody actually reviewed. The payment processing bug that got auto-approved because it looked like a routine refactor. The auth bypass that sat in a 400-line diff.
By the time you’re explaining to a regulator why your review process failed, the evidence problem has become an existential one.
What Real Evidence Looks Like
After building governance frameworks for two years, I’ve landed on three requirements for defensible review evidence:
1. Immutable Record of What Was Reviewed
Not “the PR was approved” - the actual diff content at the moment of review, hashed and timestamped.
2. Risk Classification
What made this change low-risk vs. high-risk? Was it auto-approved or did a human verify? What policy triggered escalation?
3. Independent Verification
Can someone outside your organization verify the evidence without trusting your systems?
The Infrastructure I Built
The same question kept coming up in my AI Readiness sessions: “How do we prove review quality to auditors?”
I got tired of answering “you can’t with current tools.” So I built the infrastructure.
GuardSpine CodeGuard is a GitHub Action that:
- Analyzes PR diffs against sensitive patterns (auth, payments, PII, crypto)
- Assigns risk tiers (L0 trivial through L4 critical)
- Auto-approves low-risk changes
- Escalates high-risk changes for human review
- Generates cryptographically verifiable evidence bundles
The bundle contains hash-chained events, the exact diff at analysis time, and approval records. Anyone can verify it offline.
How It Works in Practice
# .github/workflows/codeguard.yml
- uses: DNYoussef/codeguard-action@v1
with:
github_token: ${{ secrets.GITHUB_TOKEN }}
risk_threshold: L3
When a PR opens:
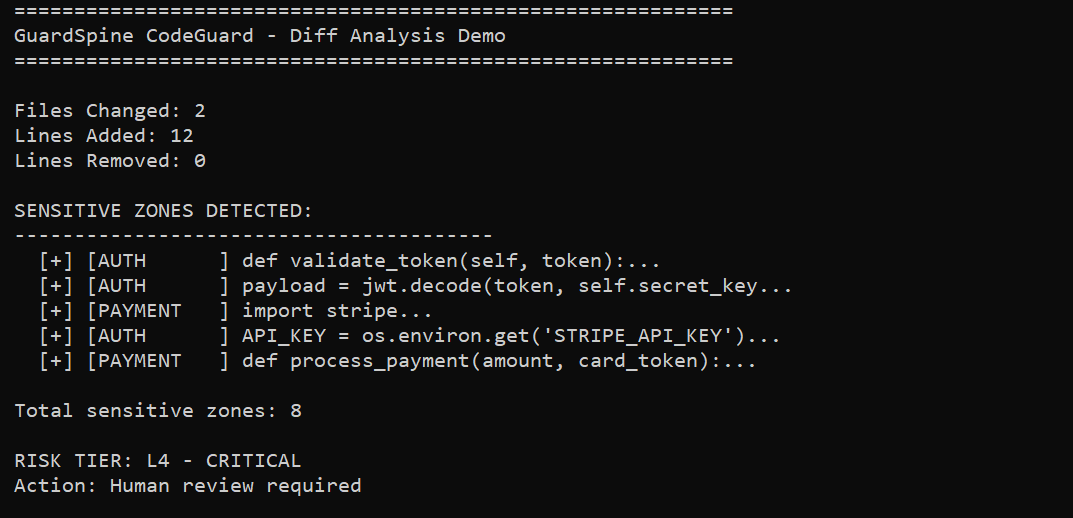
- Diff gets parsed and checked against sensitive patterns
- Risk tier assigned based on what changed
- L0-L2 auto-approved, L3-L4 require human review
- Evidence bundle generated with hash chain
The PR gets a comment showing risk tier and drivers. The bundle saves as a workflow artifact.
The Verification Story
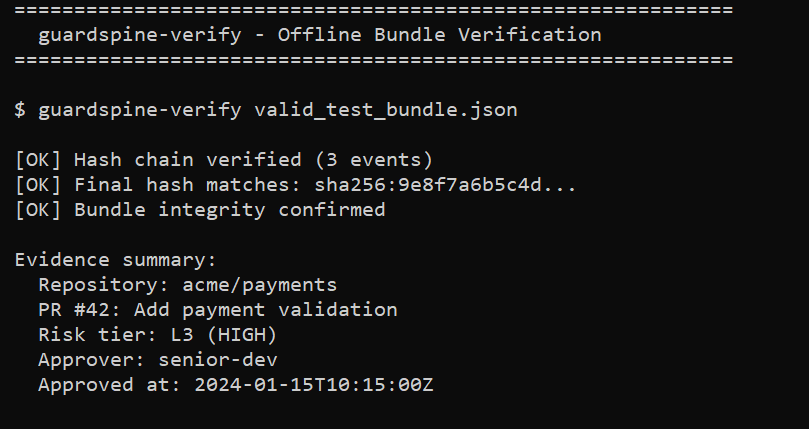
guardspine-verify evidence-bundle.json
# [OK] Hash chain verified (3 events)
# [OK] Final hash matches
# [OK] Bundle integrity confirmed
No trust required. Your auditor can verify independently.
The spec and verifier are MIT licensed. You can audit the verification logic yourself. This matters when “trust us” isn’t an acceptable answer.
The Bigger Picture
This connects to what I wrote about in Why Enterprise AI Will Fail - the constraint isn’t model quality, it’s infrastructure and governance.
GuardSpine is one piece of that infrastructure. It solves the specific problem of PR review evidence. Combined with the governance frameworks I help clients build, it creates a defensible posture that scales with AI adoption.
The teams that win will be the ones who built the guardrails before they hit the gas.
With the EU AI Act enforcement hitting August 2, 2026, the compliance clock is already running. Every AI-assisted change you ship without evidence is a liability you are accumulating, not avoiding.
Resources:
Ready to build defensible AI governance for your team?
I run AI Readiness Sessions where we map your current review processes against what auditors are actually asking for. No slides, no theory - just a working roadmap for evidence infrastructure.